
The Accuracy of the Classifier
To see how well our classifier does, we might put 50% of the data into the training set and the other 50% into the test set. Basically, we are setting aside some data for later use, so we can use it to measure the accuracy of our classifier. We've been calling that the test set. Sometimes people will call the data that you set aside for testing a hold-out set, and they'll call this strategy for estimating accuracy the hold-out method.
Note that this approach requires great discipline. Before you start applying machine learning methods, you have to take some of your data and set it aside for testing. You must avoid using the test set for developing your classifier: you shouldn't use it to help train your classifier or tweak its settings or for brainstorming ways to improve your classifier. Instead, you should use it only once, at the very end, after you've finalized your classifier, when you want an unbiased estimate of its accuracy.
Measuring the Accuracy of Our Wine Classifier
OK, so let's apply the hold-out method to evaluate the effectiveness of the $k$-nearest neighbor classifier for identifying wines. The data set has 178 wines, so we'll randomly permute the data set and put 89 of them in the training set and the remaining 89 in the test set.
shuffled_wine = wine.sample(with_replacement=False)
training_set = shuffled_wine.take(np.arange(89))
test_set = shuffled_wine.take(np.arange(89, 178))
We'll train the classifier using the 89 wines in the training set, and evaluate how well it performs on the test set. To make our lives easier, we'll write a function to evaluate a classifier on every wine in the test set:
def count_zero(array):
"""Counts the number of 0's in an array"""
return len(array) - np.count_nonzero(array)
def count_equal(array1, array2):
"""Takes two numerical arrays of equal length
and counts the indices where the two are equal"""
return count_zero(array1 - array2)
def evaluate_accuracy(training, test, k):
test_attributes = test.drop('Class')
def classify_testrow(row):
return classify(training, row, k)
c = test_attributes.apply(classify_testrow)
return count_equal(c, test.column('Class')) / test.num_rows
Now for the grand reveal -- let's see how we did. We'll arbitrarily use $k=5$.
evaluate_accuracy(training_set, test_set, 5)
The accuracy rate isn't bad at all for a simple classifier.
Breast Cancer Diagnosis
Now I want to do an example based on diagnosing breast cancer. I was inspired by Brittany Wenger, who won the Google national science fair in 2012 a 17-year old high school student. Here's Brittany:

Brittany's science fair project was to build a classification algorithm to diagnose breast cancer. She won grand prize for building an algorithm whose accuracy was almost 99%.
Let's see how well we can do, with the ideas we've learned in this course.
So, let me tell you a little bit about the data set. Basically, if a woman has a lump in her breast, the doctors may want to take a biopsy to see if it is cancerous. There are several different procedures for doing that. Brittany focused on fine needle aspiration (FNA), because it is less invasive than the alternatives. The doctor gets a sample of the mass, puts it under a microscope, takes a picture, and a trained lab tech analyzes the picture to determine whether it is cancer or not. We get a picture like one of the following:
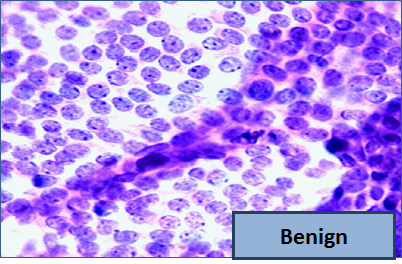
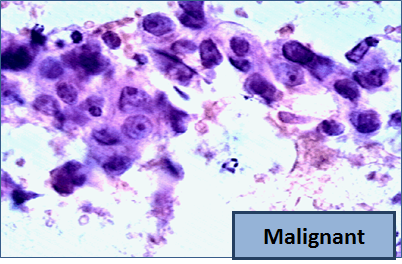
Unfortunately, distinguishing between benign vs malignant can be tricky. So, researchers have studied the use of machine learning to help with this task. The idea is that we'll ask the lab tech to analyze the image and compute various attributes: things like the typical size of a cell, how much variation there is among the cell sizes, and so on. Then, we'll try to use this information to predict (classify) whether the sample is malignant or not. We have a training set of past samples from women where the correct diagnosis is known, and we'll hope that our machine learning algorithm can use those to learn how to predict the diagnosis for future samples.
We end up with the following data set. For the "Class" column, 1 means malignant (cancer); 0 means benign (not cancer).
patients = Table.read_table(path_data + 'breast-cancer.csv').drop('ID')
patients
So we have 9 different attributes. I don't know how to make a 9-dimensional scatterplot of all of them, so I'm going to pick two and plot them:
color_table = Table().with_columns(
'Class', make_array(1, 0),
'Color', make_array('darkblue', 'gold')
)
patients_with_colors = patients.join('Class', color_table)
patients_with_colors.scatter('Bland Chromatin', 'Single Epithelial Cell Size', group='Color')

Oops. That plot is utterly misleading, because there are a bunch of points that have identical values for both the x- and y-coordinates. To make it easier to see all the data points, I'm going to add a little bit of random jitter to the x- and y-values. Here's how that looks:

For instance, you can see there are lots of samples with chromatin = 2 and epithelial cell size = 2; all non-cancerous.
Keep in mind that the jittering is just for visualization purposes, to make it easier to get a feeling for the data. We're ready to work with the data now, and we'll use the original (unjittered) data.
First we'll create a training set and a test set. The data set has 683 patients, so we'll randomly permute the data set and put 342 of them in the training set and the remaining 341 in the test set.
shuffled_patients = patients.sample(683, with_replacement=False)
training_set = shuffled_patients.take(np.arange(342))
test_set = shuffled_patients.take(np.arange(342, 683))
Let's stick with 5 nearest neighbors, and see how well our classifier does.
evaluate_accuracy(training_set, test_set, 5)
Over 96% accuracy. Not bad! Once again, pretty darn good for such a simple technique.
As a footnote, you might have noticed that Brittany Wenger did even better. What techniques did she use? One key innovation is that she incorporated a confidence score into her results: her algorithm had a way to determine when it was not able to make a confident prediction, and for those patients, it didn't even try to predict their diagnosis. Her algorithm was 99% accurate on the patients where it made a prediction -- so that extension seemed to help quite a bit.